专业赛事推荐平台 内存暴降50倍且精度无损, MIT提议耀眼力匹配, 能拆伙大模子显存危险吗?

编订|Panda
想象这么一个场景:你正盯着屏幕,看着你的自主AI智能体(比如OpenClaw)跋扈地运作。

它正在自主审查一个包含数十万行代码的史诗级开源方法,穿梭于无数的文献、API文档和调试日记之间。它弘扬得像一个不知疲钝的超等法子员,但在这「无所不可」的表象之下,散失着一个随时可能引爆的硬件梦魇——跟着高低文变得越来越长,大模子的「责任挂念」正在暴涨,像一个无底洞一样,冷凌弃地团结着爽脆的GPU显存池!
这个令通盘企业级AI建造者三十六策,走为善策的显存杀手,便是KVCache。
但目下,惩处决议来了,来自麻省理工学院(MIT)的臆测团队(AdamZweiger、XinghongFu等东说念主)。他们建造出了一种名为「耀眼力匹配」(AttentionMatching)的全新潜在空间(LatentSpace)压缩时刻。

论文标题:FastKVCompactionviaAttentionMatching
代码地址:https://github.com/adamzweiger/compaction
其粗略在短短几秒钟内,将大型谈话模子的高低文内存跋扈压缩高达50倍,且真实莫得任何精度赔本!
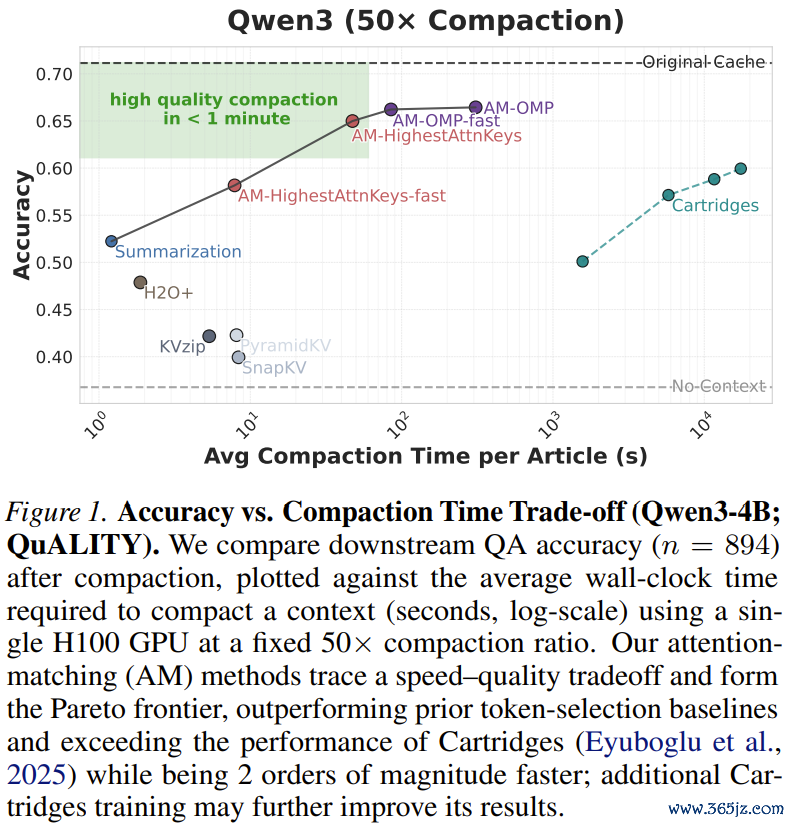
这意味着本来需要一通盘这个词H100GPU阵列才能勉强撑抓的超长对话或巨型文档分析任务,目下可能只需要单张显卡就能松驰跑满并发。一场对于AI基础设施的效果创新,似乎已悄然打响。
爽脆的责任挂念
大模子的阿喀琉斯之踵
要交融这项时刻有何等逆天,咱们必须先直视大模子的软肋。
LLM是自归来的,它们生成回适时是逐token往外吐的。为了幸免在瞻望每一个新词时,齐要把长达几万字的聊天记载从新到尾从新磋磨一遍,模子必须将之前处理过的每一个token的「数学灵魂」缓存起来——这些被提真金不怕火出来的多维向量,便是「键(Key)」和「值(Value)」对,即KVCache。
跟着高低文的拉伸,这层责任挂念会不可逆转地推广。
在当代企业级欺骗中,比如分析成百上千页的法律协议、保管长达数月的私东说念主AI伴侣挂念,或者运行OpenClaw这么的自治编码智能体,单单一个用户的苦求,其KVCache就能陡然飙升到数十GB。
正如论文第一作家AdamZweiger所言:「在超长高低文业绩中,KVCache是最大的物理瓶颈。它不仅死死锁住了并发量,将就你舒缓批处理畛域,致使逼着系统进行极其影响性能的时常卸载。」
靠近这个吞金兽,臆测者们曾尝试过好多决议:
Token丢弃与合并(如H2O,SnapKV,PyramidKV等):这些步调试图踢掉那些模子认为「不遑急」的token。在轻度压缩时还能勉强,但一朝将压缩率拉高(比如试图压缩10倍以上),模子的本事就会遭受断崖式着落。
文本选录:这是目下工业界最无奈的标配。当内存见底时,系统暂停,让模子我方写一段高低文总结,然后清空原有挂念。这种步调相等「有损」,会把极其要道的眇小细节(比如医疗记载里的一个漠视办法)透澈抹除。
潜空间压缩(如Cartridges):这是近期的前沿探索,阐明了高比例压缩不仅可行,而且还能保抓高精度。但它的代价极其爽脆:它需要通过极其慢慢的端到端梯度下降来老师这些压缩后的挂念。为了压缩一段高低文,哪怕动用爽脆的GPU,也需要消费数小时!这在条件「秒回」的及时企业欺骗中,真实是言而无信。
咱们需要一种既有Cartridges的精度,又有传统步调速率的终极魔法。而MIT的「耀眼力匹配」,恰是为此而生。
冲突常理的数学魔法
「耀眼力匹配」的底层逻辑
MIT的臆测东说念主员莫得死磕慢慢的机器学习老师,而是想出了一个绝妙的数学捷径。他们退后一步,问了一个极其骨子的问题:当咱们压缩挂念时,模子究竟在乎什么?
谜底是:模子根底不在乎你存了些许个Key和Value,它只在乎当它抛出一个查询(Query,2026世界杯比赛买输赢中国官网即q)时,这堆挂念能给它复返什么戒指!
为了齐备骗取AI,让它认为「压缩后的挂念和本来雄壮的挂念一模一样」,压缩后的键值对(C_k,C_v)必须严格匹配原始挂念的两个中枢数学属性:
耀眼力输出(AttentionOutput):这是AI提真金不怕火到的执行信息向量。
耀眼力质料(AttentionMass):这是极其要道的极少。在拼接新token或旧挂念时,一段挂念的话语权取决于它的「质料」。
要是你径直把1000个token压缩成20个,那么这20个token的「总质料」豪阔拼不外本来的1000个,这会导致模子在后续推理时,相等看不起这部分被压缩的挂念。为了破解这个死局,臆测团队引入了一个眇小但号称神来之笔的变量:每token标量偏差β。
这个β偏差就像是一个「杠杆权重」,它在耀眼力磋磨的指数层面上对保留住来的Key进行乘法重加权,让戋戋1个被保留的Key,粗略爆发出代表50个被移除Key的巨大「质料」!
要是用严谨的数学谈话(如论文中的公式1和2)来抒发,他们要优化的标的便是找到(C_k,β,C_v),使得对于通盘干系的查询q:
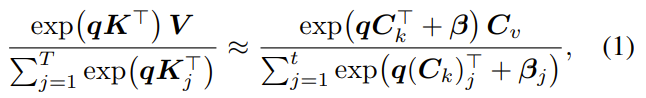
而且匹配总质料:
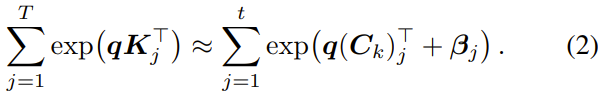
更惊东说念主的是,由于这种精妙的框架构建,这个看似复杂的非线性优化问题,果然天然则然地解体了!臆测东说念主员完全舍弃了吃算力的反向传播和梯度优化。
最初,锁定C_k后,质料匹配问题退化成了一个非负最小二乘法(NNLS)问题,陡然就能磋磨出偏差β。
随后,耀眼力输出匹配问题径直酿成了一个圭臬的平常最小二乘法(OLS)问题,通过浅显的代数矩阵运算,斯须就能求出压缩后的值C_v!
这真实是降维打击。本来需要数小时的老师,被线性代数优化到了以「秒」为单元。
来自VentureBeat,由AI生成
预判你的预判
若何提真金不怕火「参矜重询」与挑选「金钥匙」?
有了数学火器,专业赛事推荐平台接下来的工程落地相似惊艳。为了让压缩算法知说念该保留什么,系统需要一批「参矜重询」(Q_ref),看成模子将来可能提议的问题的「替身」。
臆测团队想象了极其聪敏的「预演」机制:
重叠预填充:暗暗在文档末尾加一句荫藏提示:「重叠前边的高低文」,然后拿获模子在试图复述时产生的里面Query向量。
自我学习:让模子对文档进行快速的合成任务,比如「提真金不怕火通盘中枢事实」或「把日历结构化为JSON」,从而嗅探出模子在深度推理时会生成什么样的Query。
手里攥着这些极具代表性的Query探针,系统开动从原始的茫茫Key海中挑选「金钥匙」(C_k)。论文中提供了两种步调:
最高耀眼力法(HighestAttentionKeys):这是一种闪电般的启发式步调,径直挑出在参矜重询中被顾惜度最高的Keys。速率极快,性价比超高。
正交匹配跟踪(OrthogonalMatchingPursuit,OMP):这是一种愈加极客和缠绵的算法。它像搭积木一样,每一步齐精挑细选一个最能填补「质料舛误」残差的Key,然后用NNLS从新校准权重。固然略微耗时(还是只是几分钟级别),但能将压实质料推向巅峰(AM-OMP)。

并非通盘「耀眼力」生来对等
非均匀压缩战术
这还不是重心,在真切探索模子架构时,他们发现了一个羡慕的表象:在多头耀眼力机制中,并非通盘的「头」齐是责任狂。
有些Head相等缠绵,需要雄壮的KV容量才能保抓性能(比如厚爱长程依赖的Head);而另一些Head则极其佛系,哪怕你把它的挂念砍掉90%,它还是能齐备运转(比如只顾惜局部词法结构的Head)。
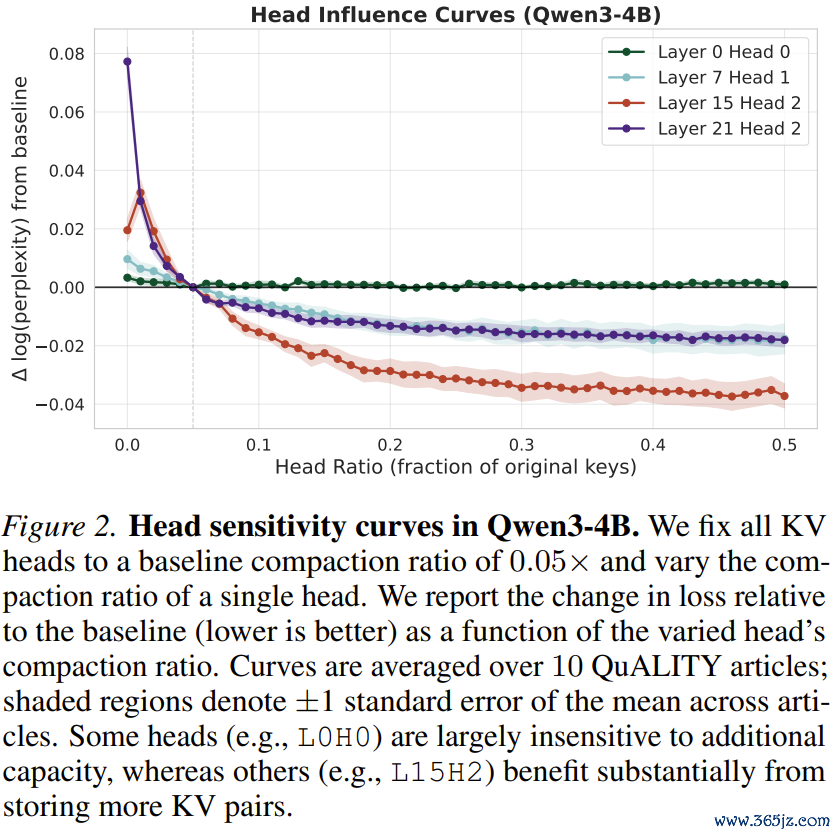
基于这个知悉,团队建造了非均匀压缩(NonuniformCompaction)战术:为每一个模子事前磋磨了一条「明锐度弧线」,就像是给每一个耀眼力头进行了一次体检。在执行压缩时,系统不再是一刀切,而是将极其可贵的显存预算,歪斜分派给那些对信息最明锐的「中枢Head」。这一战术的引入,径直让压缩后的模子性能终明晰质的飞跃!
即使在像Gemma-3-12B这种多半使用了滑动窗口耀眼力的羼杂架构模子上,耀眼力匹配还是弘扬出了惊东说念主的合适性和鲁棒性。
压力测试
见证遗迹的时刻
为了考证这项时刻是否确实能在现实全国的绞肉机中存活,臆测东说念主员采选了Qwen3-4B、Llama3.1-8B和Gemma3-12B,并将它们扔进了两个截然相背的测试场。
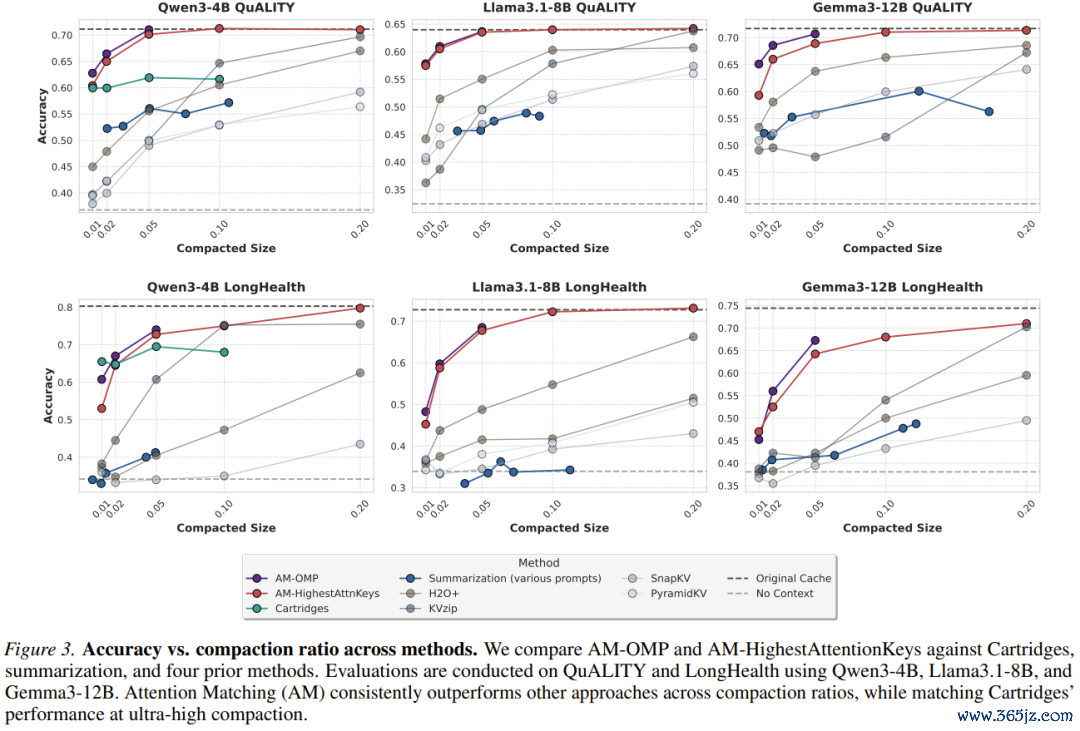
1.QuALITY基准测试:秒杀全场
在这个包含5000到8000词的圭臬阅读交融测试中,AttentionMatching在50倍的极限压缩比下,只是耗时几秒到一分钟(取决于是否使用OMP算法),就透澈打爆了H2O+、SnapKV、KVzip等通盘基于token编订的前辈。它的准确率弧线牢牢咬住了耗时数小时的Cartridges,讲解了什么是「快、准、狠」。
2.LongHealth医疗卷宗:传统决议的坟茔
这是一个代表信得过企业级挑战的数据集。整整60,000个token,塞满了多个患者复杂的病历、化验单和用药记载,信息密度极高。
在这个测试中,工业界最爱用的「文本选录」透澈沦为笑柄——它的准确率跌到了和「不提供任何高低文(No-Context)」一模一样的底线,意味着模子看了选录等于没看。
而AttentionMatching则犹如战神附体,大幅卓著了通盘传统权宜之策。
天然,Zweiger也坦诚地给出了工程建议:「对于这种极高信息密度的任务,要是你想保留通盘细节,建议将压缩比调得善良一些(比如10倍或20倍),以调换豪阔的精准度。」
3.AIME2025在线动态压缩:遨游中换引擎
最让东说念主豪言壮语的,是针对在线压缩的看法考证。靠近AIME顶级数学推理题,臆测东说念主员锁死了物理内存上限。模子就像是在一个狭窄的笼子里进行相等消耗脑力的磋磨。
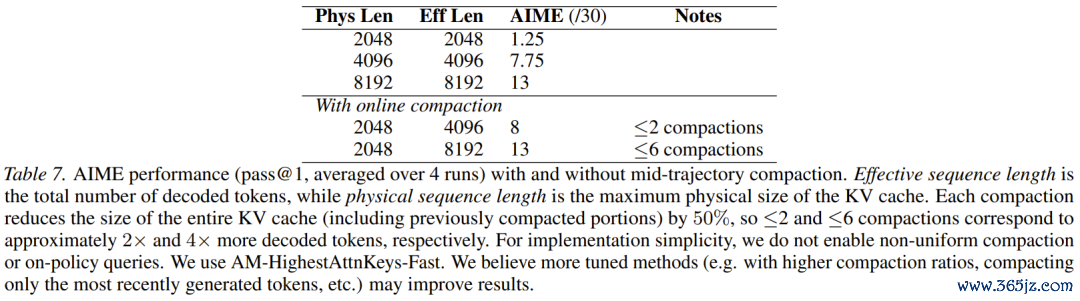
每当内存爆满,系统就会陡然按下暂停键,用AttentionMatching将其责任挂念暴力压缩50%,然后让模子赓续想考!即使在一次解题经由中,连气儿六次「切除」一半的挂念,模子最终还是告成找到了正确谜底,其弘扬与领有无穷内存的模子完全一致。
这对于OpenClaw这么需要万古辰运行、不断产生冗长用具调用日记的Agent来说,真实是救命稻草!
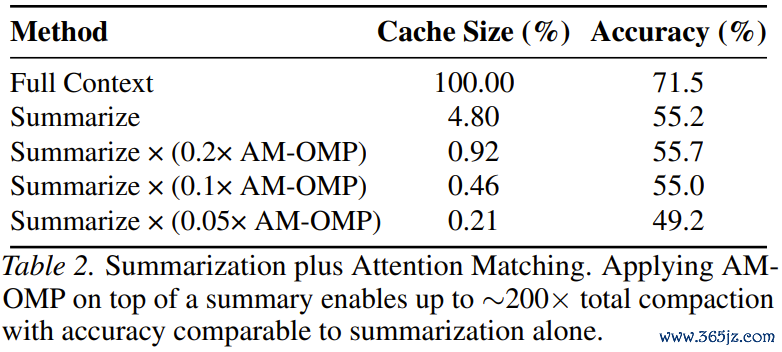
致使,对于那些追求压缩率、对精度条件稍优容的场景,臆测东说念主员还玩出了一种「200倍压缩」的组合技:先让模子生成文本选录,然后再对选录的KVCache进行AttentionMatching压缩!最终在微乎其微的显存占用下,达到了与纯选录一样的准确率。
结语
从建造者自救到大厂标配的范式漂泊?
天然,莫得任何魔法是莫得代价的。
必须指出的是,要是你靠近的是极其复杂的数据,而且非要追求100倍以上压缩,那么慢慢的、基于梯度优化的Cartridges还是能在精度上险胜一筹,因为它能在更繁密的潜空间中搜索最优解,而不受限于「从原始Key中挑选」的设定。
此外,这套神技目下还不是一个不错「无脑装配」的插件软件。正如Zweiger解释的那样:「潜空间压缩是一种模子层的时刻。你必须领有探望模子权重的权限。」这意味着,要是你完全依赖闭源的API(比如径直调用GPT-4接口),你是无法我方终了这套魔法的。企业要想享受这种显存目田,必须拥抱开源权重模子(如Llama3、Qwen3)。
而且,要将这种潜空间KV压缩时刻编织进当代极其复杂的商用推理引擎(那些早已布满了前缀缓存、变长内存打包等复杂手段的系统)中,还是需要工程师们掉光不少头发。
但趋势已无可违犯。正如Zweiger所预言的:「咱们正在见证高低文压缩发生根人性的范式漂泊——它正从『企业我方拼凑的鄙俚工程』,进化为『底层模子提供商内置的核火器』。比如OpenAI最近推出的黑盒压缩端点,复返的便是一个不透明的对象,而不是纯文本选录。」
当「耀眼力匹配」透澈融入AI基础设施的血液中时,显存瓶颈将被透澈击碎。到其时,像OpenClaw这么的智能体,也许确实粗略以单机之躯,费解通盘这个词全国的常识。
开云kaiyun中国手机APP下载参考团结专业赛事推荐平台